| plots | ||
| .gitignore | ||
| debug_distance.py | ||
| eval.py | ||
| generate_data.py | ||
| Makefile | ||
| README.md | ||
| requirements.txt | ||
| train.py | ||
CityBert
CityBert is a machine learning project that fine-tunes a neural network model to understand the similarity between cities based on their geodesic distances.
The project generates a dataset of US cities and their pair-wise geodesic distances, which are then used to train the model.
The project can be extended to include other distance metrics or additional data, such as airport codes, city aliases, or time zones.
Note that this model only considers geographic distances and does not take into account other factors such as political borders or transportation infrastructure. These factors contribute to a sense of "distance as it pertains to travel difficulty," which is not directly reflected by this model.
But Why?
Demonstrate Flexibility
This project showcases how pre-trained language models can be fine-tuned to understand geographic relationships between cities.
Contribute to the Community
Out-of-the-box neural network models struggle to grasp the spatial relationships, cultural connections, and underlying patterns between cities that humans intuitively understand. Training a specialized model bridges this gap, allowing the network to capture complex relationships and better comprehend geographic data.
By training a model on pairs of city names and geodesic distances, we enhance its ability to infer city similarity based on names alone. This is beneficial in applications like search engines, recommendation systems, or other natural language processing tasks involving geographic context.
This model will be published for public use, and the code can be adapted for other specialized use-cases.
Explore Tradeoffs
Using a neural network to understand geographic relationships provides a more robust and flexible representation compared to traditional latitude/longitude lookups. It can capture complex patterns and relationships in natural language tasks that may be difficult to model using traditional methods.
Although there's an initial computational overhead in training the model, benefits include handling various location-based queries and better handling of aliases and alternate city names.
This tradeoff allows more efficient and context-aware processing of location-based information, making it valuable in specific applications. In scenarios requiring high precision or quick solutions, traditional methods may still be more suitable.
Ultimately, the efficiency of a neural network compared to traditional methods depends on the specific problem and desired trade-offs between accuracy, efficiency, and flexibility.
Applicability to Other Tasks
The approach demonstrated can be extended to other metrics or features beyond geographic distance. By adapting dataset generation and fine-tuning processes, models can be trained to learn various relationships and similarities between different entities.
Overview of Project Files
generate_data.py: Generates a dataset of US cities and their pairwise geodesic distances.train.py: Trains the neural network model using the generated dataset.eval.py: Evaluates the trained model by comparing the similarity between city vectors before and after training.Makefile: Automates the execution of various tasks, such as generating data, training, and evaluation.README.md: Provides a description of the project, instructions on how to use it, and expected results.requirements.txt: Defines requirements used for creating the results.
How to Use
- Install the required dependencies by running
pip install -r requirements.txt. - Run
make city_distances.csvto generate the dataset of city distances. - Run
make trainto train the neural network model. - Run
make evalto evaluate the trained model and generate evaluation plots.
You can also just run make (i.e., make all) which will run through all of those steps.
What to Expect
After training, the model should be able to understand the similarity between cities based on their geodesic distances.
You can inspect the evaluation plots generated by the eval.py script to see the improvement in similarity scores before and after training.
After one epoch, we can see the model has learned to correlate our desired quantities:
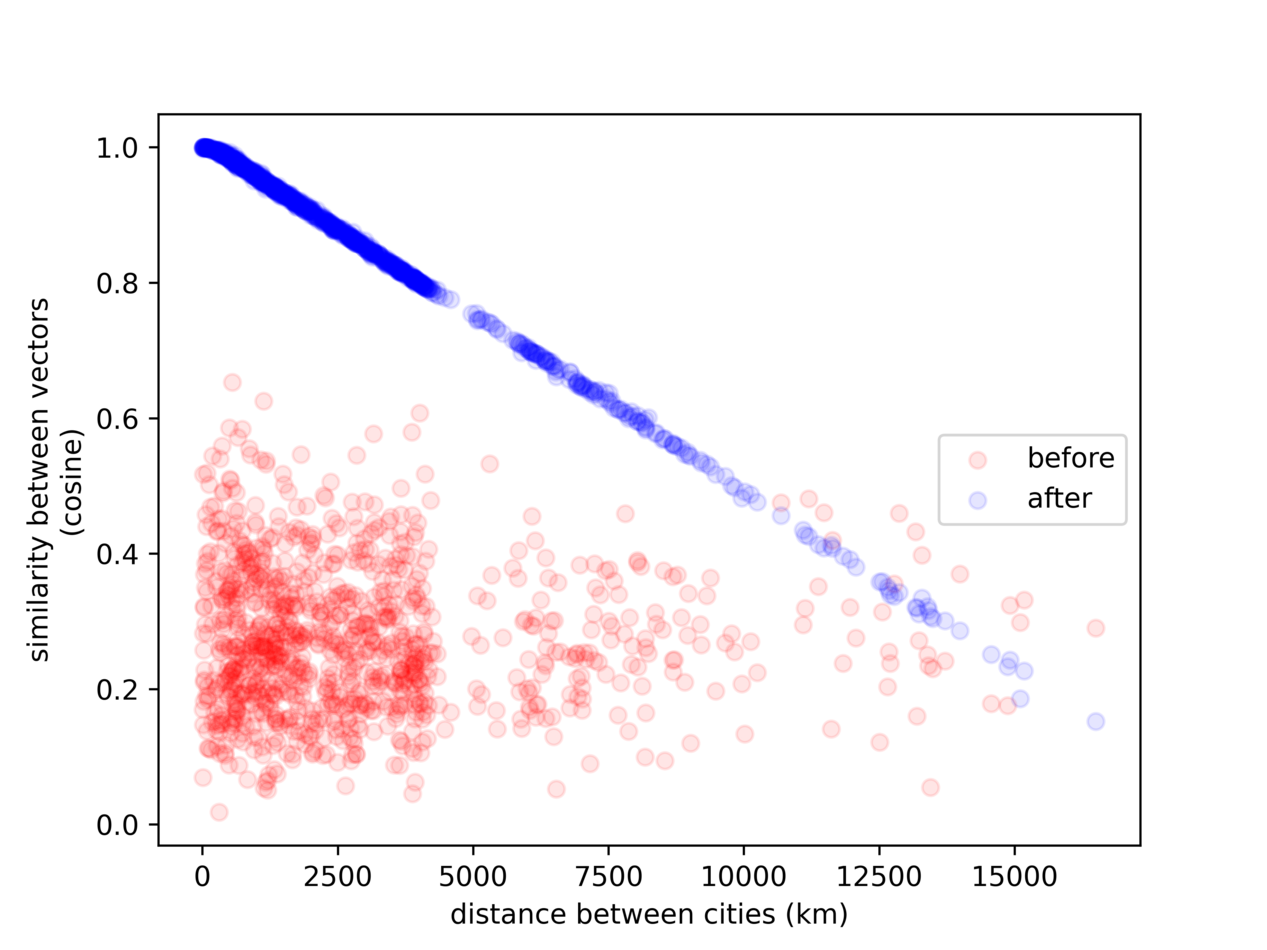
The above plot is an example showing the relationship between geodesic distance and the similarity between the embedded vectors (1 = more similar), for 10,000 randomly selected pairs of US cities (re-sampled for each image).
Note the (vertical) "gap" we see in the image, corresponding to the size of the continental United States (~5,000 km)
Future Improvements
There are several potential improvements and extensions to the current model:
- Incorporate airport codes: Train the model to understand the unique codes of airports, which could be useful for search engines and other applications.
- Add city aliases: Enhance the dataset with city aliases, so the model can recognize different names for the same city. The
geonamescachepackage already includes these. - Include time zones: Train the model to understand time zone differences between cities, which could be helpful for various time-sensitive use cases. The
geonamescachepackage already includes this data, but how to calculate the hours between them is an open question. - Expand to other distance metrics: Adapt the model to consider other measures of distance, such as transportation infrastructure or travel time.
- Train on sentences: Improve the model's performance on sentences by adding training and validation examples that involve city names in the context of sentences. Can use generative AI to create template sentences (mad-libs style) to create random and diverse training examples.
- Global city support: Extend the model to support cities outside the US and cover a broader range of geographic locations.
Notes
- Generating the data took about 13 minutes (for 3269 US cities) on 8-cores (Intel 9700K), yielding 2,720,278 records (combinations of cities).
- Training on an Nvidia 3090 FE takes about an hour per epoch with an 80/20 test/train split and batch size 16, so there were 136,014 steps per epoch. At batch size 16 times larger, each epoch took about 14 minutes.
- Evaluation (generating plots) on the above hardware took about 15 minutes for 20 epochs at 10k samples each.
- WARNING: It is unclear how the model performs on sentences, as it was trained and evaluated only on word-pairs. See improvement (5) above.